Python 多线程编程参考。
关于线程
线程是操作系统的最小调度单位,属于进程。如果将操作系统比较工厂,那么进程就属于车间,而线程就是具体的工人。
使用 Tread 类
Python 中线程的模块是 treading, 我们先看一个简单的例子:
先导入包,定义好我们需要的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import timeimport threadingdef get_detail_html (url ): """模拟爬取网页内容的操作""" print ('get detail started' ) time.sleep(2 ) print ('get detail end' ) def get_detail_url (url ): """模拟获取网页地址的操作""" print ('get url started' ) time.sleep(2 ) print ('get url end' )
进行我们第一个测试:
1 2 3 4 5 6 7 8 9 10 11 12 if __name__ == '__main__' : thread1 = threading.Thread(target=get_detail_html, args=("" ,)) thread2 = threading.Thread(target=get_detail_url, args=("" ,)) start_time = time.time() thread1.start() thread2.start() print (time.time() - start_time)
查看执行结果:
1 2 3 4 5 get detail started get url started 0.0020024776458740234 get detail end get url end
设置守护线程可以让主线程结束后将子线程都 kill 掉:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if __name__ == '__main__' : thread1 = threading.Thread(target=get_detail_html, args=("" ,)) thread2 = threading.Thread(target=get_detail_url, args=("" ,)) thread1.setDaemon(True ) thread2.setDaemon(True ) start_time = time.time() thread1.start() thread2.start() print (time.time() - start_time)
主线程执行完毕后,其它子线程也将结束(在 jupyter 中不一样)
1 2 3 get detail started get url started 0.0010001659393310547
同时线程还有一个 join 方法,可以造成阻塞并等待前面的线程结束之后才运行后面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if __name__ == '__main__' : thread1 = threading.Thread(target=get_detail_html, args=("" ,)) thread2 = threading.Thread(target=get_detail_url, args=("" ,)) start_time = time.time() thread1.start() thread2.start() thread1.join() thread2.join() print (time.time() - start_time)
继承 Tread 类
我们也可以继承 treading.Tread 类实现多线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class GetDetailHtml (threading.Thread ): def run (self ): """模拟爬取网页内容的操作""" print ('get detail started' ) time.sleep(2 ) print ('get detail end' ) class GetDetailURL (threading.Thread ): def run (self ): """模拟获取网页地址的操作""" print ('get url started' ) time.sleep(2 ) print ('get url end' ) if __name__ == '__main__' : thread1 = GetDetailHtml() thread2 = GetDetailURL() start_time = time.time() thread1.start() thread2.start() thread1.join() thread2.join() print (time.time() - start_time)
线程间通信
前面提供了两个函数,一个是负责去抓 url,一个是去爬取 url 的内容,那么对于抓到的 url,你需要有一种方式传给爬取内容的函数,这就是线程之间需要通信的例子。
线程中通信有几种方案:
使用全局变量
使用 Python 中的队列,即 queue
线程同步
在之前关于 GIL 的文章中,有一个多线程加减的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import threadingtotal = 0 def add (): global total for i in range (1000000 ): total += 1 def desc (): global total for i in range (1000000 ): total -= 1 thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print (total)
当我们查看上面代码的字节码的时候,可以看到大概的步骤如下:
加载 total 到内存
加载 1
进行加法操作
赋值给 total (多线程状态下,赋值会出错)
上述代码,每次的结果都不一样,就是因为在上面4个步骤的任意一个步骤中,GIL 都有可能被释放,然后加载的变量被其他的线程修改了。
这里就引出我们的线程的同步机制,即我们设置一种方法,让某一段代码执行完毕之后,才能切换到别的线程执行,这就保证了在修改数据的时候,不会出错。
锁 Lock
同步机制可以使用锁来实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from threading import Lockimport threadingtotal = 0 lock = Lock() def add (): global total global lock for i in range (10000 ): lock.acquire() total += 1 lock.release() def desc (): global total global lock for i in range (10000 ): lock.acquire() total -= 1 lock.release() thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() print (f"Total is: {total} " )
但是使用锁,也优缺点,第一个是性能上的损失,另外是容易引起死锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 lock.acquire() lock.acquire() def do_something (lock ): lock.acquire() lock.acquire() do_something(lock)
针对第三种情况,Python 有一种 RLock(可以重复申请的锁), 可以让你连续申请锁,但是注意,申请和释放的次数要一样。
1 2 3 4 5 6 7 from threading import RLocklock.acquire() lock.acquire() lock.release() lock.release()
条件变量 Condition
假设有一个需求是,需要设计一个对话系统,让两个人可以互相对话,即他们说话的顺序需要是交互的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import threadingfrom threading import Conditionclass A (threading.Thread ): def __init__ (self, cond ): super ().__init__(name='A' ) self.cond = cond def run (self ): with self.cond: print (f"{self.name} , 1" ) self.cond.notify() self.cond.wait() print (f"{self.name} , 3" ) self.cond.notify() self.cond.wait() class B (threading.Thread ): def __init__ (self, cond ): super ().__init__(name='B' ) self.cond = cond def run (self ): with self.cond: self.cond.wait() print (f"{self.name} 2" ) self.cond.notify() self.cond.wait() print (f"{self.name} 4" ) self.cond.notify() if __name__ == '__main__' : cond = Condition() a = A(cond) b = B(cond) b.start() a.start()
为什么notify 和 wait,必须在 with 语句中呢?condition 内部有两把锁
第一底层锁,控制 condition 的进入,即通过 with 或者 cond.acquire()。在这里 B 通过 with 语句进入 condition 内部后,它调用了 wait 方法,wait 内部首先会将底层锁释放,这样 a 才可以通过 wiht 语句进入 condition。
随后,在 wait 方法内,它还会申请一把新的锁放入condition的等待队列(双端队列)中,等待 notify 方法的唤醒
了解了这个原理,上面的问题就很简单了,如果不先通过 with 语句,我们是无法进入到 condition 内部的。
Condition 也有类似锁的申请、释放的模式:
1 2 3 self.cond.acquire() self.cond.release()
信号量 Semaphore
Semaphore 是用于控制进入数量的锁。
比如在文件的操作中,需要控制读写线程的数量。在爬虫的实现中,需要限制请求并发数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from calendar import cimport threadingimport timeclass HtmlSpider (threading.Thread ): """HTML 爬取模拟器。 Args: threading (Thread): 继承自线程类,每个 URL 有一个线程处理 """ def __init__ (self, url, sem ): super ().__init__() self.url = url self.sem = sem def run (self ): time.sleep(2 ) print (f"{self.url} finished." ) self.sem.release() class UrlMaker (threading.Thread ): def __init__ (self, sem ): super ().__init__() self.sem = sem def run (self ): for i in range (100 ): self.sem.acquire() html_sider = HtmlSpider(f"http:/scottzhang.pro/{i} " , self.sem) html_sider.start() if __name__ == '__main__' : sem = threading.Semaphore(10 ) url_maker = UrlMaker(sem) url_maker.start()
信号量内部实际上是使用 condition 实现的,而 condition 则是使用 queue 实现的。
ThreadPoolExecutor 线程池
使用
线程池也可以实现 semaphore 的功能,即控制线程的数量。
但是线程池可以控制的东西更多,比如它可以获得某个线程的状态与返回值。
当一个线程完成的时候,主线程可以立即知道。
其次,futures 可以让多线程和多进程编码接口一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import loggingfrom concurrent.futures import ThreadPoolExecutorfrom concurrent.futures import as_completedimport timedef thread_function (name ): """模拟某个函数的执行""" logging.info("Thread %s: starting" , name) time.sleep(2 ) logging.info("Thread %s: finishing" , name) def start_thread_1 (): logging.info("# Start thread with method 1" ) executor = ThreadPoolExecutor(max_workers=2 ) task1 = executor.submit(thread_function, ('A thread' )) task2 = executor.submit(thread_function, ('B thread' )) task3 = executor.submit(thread_function, ('C thread' )) print (f"Task 1 status: {task1.done()} " ) print (f"Cancel task 3: {task3.cancel()} " ) def start_thread_2 (names ): logging.info("# Start thread with method 2" ) executor = ThreadPoolExecutor(max_workers=2 ) all_tasks = [ executor.submit(thread_function, (x)) for x in names ] for future in as_completed(all_tasks): data = future.result() def start_thread_3 (names ): logging.info("# Start thread with method 3" ) with ThreadPoolExecutor(max_workers=3 ) as executor: data = executor.map (thread_function, names) if __name__ == "__main__" : format = "%(asctime)s: %(message)s" logging.basicConfig(format =format , level=logging.INFO, datefmt="%H:%M:%S" ) names = ['A thread' , 'B thread' , 'C thread' ] start_thread_1() start_thread_2(names) start_thread_3(names)
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 15:36:09: # Start thread with method 1 15:36:09: Thread A thread: starting 15:36:09: Thread B thread: starting Task 1 status: False Cancel task 3: True 15:36:09: # Start thread with method 2 15:36:09: Thread A thread: starting 15:36:09: Thread B thread: starting 15:36:09: Thread C thread: starting 15:36:11: Thread B thread: finishing 15:36:11: Thread A thread: finishing 15:36:11: Thread C thread: finishing 15:36:11: Thread A thread: finishing 15:36:11: # Start thread with method 3 15:36:11: Thread A thread: starting 15:36:11: Thread B thread: starting 15:36:11: Thread B thread: finishing 15:36:13: Thread B thread: finishing 15:36:13: Thread C thread: starting 15:36:13: Thread A thread: finishing 15:36:15: Thread C thread: finishing
另外 concurrent.futures 中还有 wait 方法,可以用来阻塞。比如你想指定某个或者某些任务完成才继续:
1 2 3 4 5 6 7 from concurrent.futures import wait, FIRST_COMPLETEDexecutor = ThreadPoolExecutor(max_workers=2 ) all_tasks = [executor.submit(thread_function, (x)) for x in names] wait(all_task) wait(all_task, return_when=FIRST_COMPLETED)
理解 Future 类
当我们调用时:
= executor.submit(thread_function, ('A thread' ))task1 是一个 Future 类的实例,这个实例贯穿我们整个多线程的体系中。
因为 Python 为了提供系统的一致性,将多线程、多进程以及协程都采用了一样的设计模式。
仔细想一下,我们的 thread_function 函数并没有去访问任何 Future 实例,为什么它却可以拿到 函数的执行状态呢?
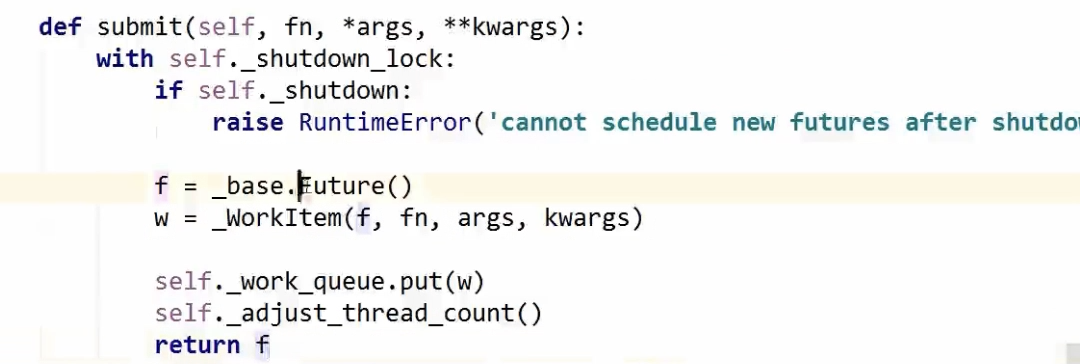
我们看一下 submit 的源码:
image.png
其中 f 为 future 类实例;w 为 workitem 实例;workitem 负责了将 future 实例和我们的函数,以及其参数做绑定。
并将 w 放到队列中。